How our new Past Grant Search fed Google’s hungry spider
One of the most-used features of The National Lottery Community Fund’s website is our legacy funded projects search tool. It has a large dataset of over 200,000 grants, across hundreds of funding programmes, dating back to the mid-2000s. It’s been running on our legacy website, which our Digital team has been gradually replacing since mid-2017.
Many thousands of people use this search function every week to find out what projects we’ve funded near them and to research successful grants to help with their own application. Now, following extensive user feedback and a few development challenges, we have a faster more user-friendly search function and we’d like to share the journey of how we got to our new Past Grants Search tool.

User feedback and insights are key
Our first step was to consider our users’ needs. With limited analytics data available on the legacy search tool, we added basic tracking to see which of the search filters (eg keyword, local authority, funding size) were used the most (and least). We also added an interim page, which asked users to tell us what they were searching for when they came to the funded projects search page.

On the interim page, visitors could still use our grants database, but also try out a third-party search tool called GrantNav. This service, run by 360Giving, provides data from The National Lottery Community Fund as well as data from almost 100 other funders across the UK. It’s quick and very user-friendly. The interim page worked well as it allowed us to gather real user feedback and insights on what our customers felt was important.
You’re only as strong as your data
Armed with a sense of what our users needed from the page, we were ready to prototype a new search tool - but we needed data. 360Giving were able to give us downloads of all The National Lottery Community Fund grant data in a standardised format they devised.
This data was structured as JavaScript Object Notation or JSON, which was ideal for us as we planned to explore using MongoDB, an “NoSQL” database, which stores data as a freeform document, rather than strictly related columns and rows. This would allow us to automatically ‘facet’ the data, grouping it by location, funding size bounds, recipient organisation, etc. This type of database is also great at storing and searching through data that comes with different fields/parameters and is ideal for a dataset that has evolved over several decades.
Soon we’d written a basic search Application Programming Interface (API) - a software tool to allow the exchange of data between different platforms - which returned information in response to a query. It meant that we could construct queries (eg "how many projects did we fund in Yorkshire in 2009") and receive raw data quickly and easily. We spent a while fine-tuning this tool to ensure results were accurate and relevant. We also worked on optimising the speed of the API so that searches felt fast for the end user - something the old search tool struggled with.

Over 200,000 grant records, indexed and searchable
The Fund’s Data team helped us finesse the data and gave us updated versions so we could increase the scope of the search. Once we were happy with this data layer, we built an interface for it. We started with a very simple search, featuring a query input and some basic sorting filters.
Our Digital Designer, Lynsey Reynolds, worked on incorporating the user feedback and the available data into a clean and usable interface. We added JavaScript enhancements so that the search results would update in real time as the users added/removed filters. Meanwhile, our Software Developer, David Rapson, worked hard to ensure the search wouldn’t depend on JavaScript and would work as expected even if our real-time version encountered a bug.
In a short time, we had an initial alpha version of the new search ready for internal testing by The National Lottery Community Fund staff. After Quality Assurance by our IT department and final testing, we were ready to launch to the public.
The icing on the cake
A couple of weeks after the new tool went live we had a huge surprise. The database powering the grants data began to complain about very high Central Processing Unit (CPU) usage. This meant the search was running slowly, or sometimes failing to load any results at all. Here’s how that looked:
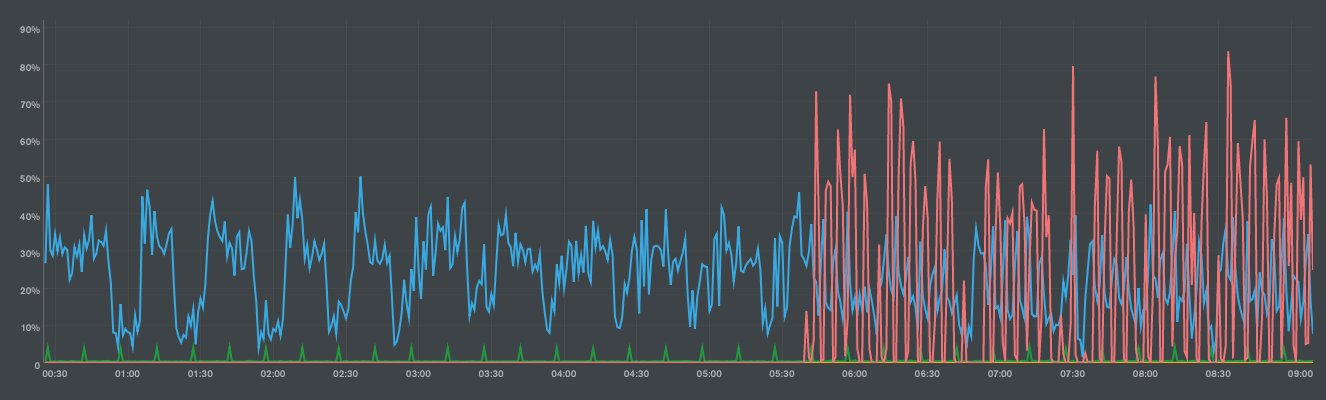
Google’s ‘spider’ had discovered the new search, and was hungrily chomping away at all of the new pages it had found. It was unable to reach these pages on the old search, so we’d inadvertently introduced quite a few new items to its index. Over 700,000 to be exact!
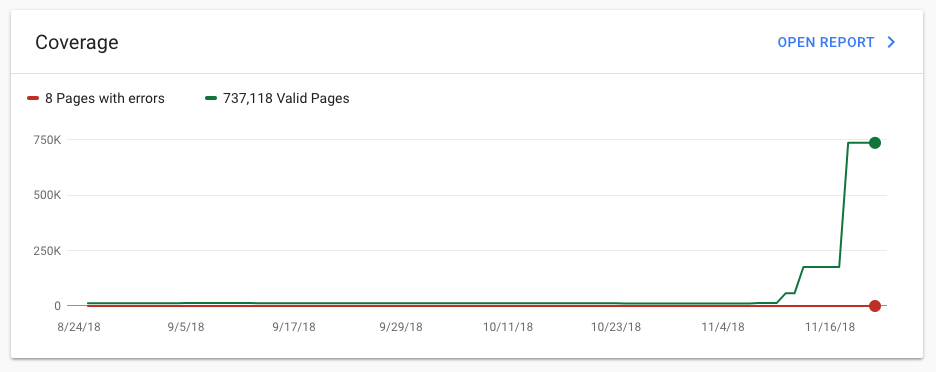
Although it was causing us issues, it also meant that for the first time, all of our funding recipients were now listed in Google. Many more people searching the web will now be able to discover projects we've funded, and hopefully some of them will even apply for funding themselves off the back of these discoveries.
Our past informs our future
Today, our Past Grant Search tool receives about three times the page views of the legacy tool, and loads results much more quickly and accurately. We still include links to the legacy search—for now—and the GrantNav data.
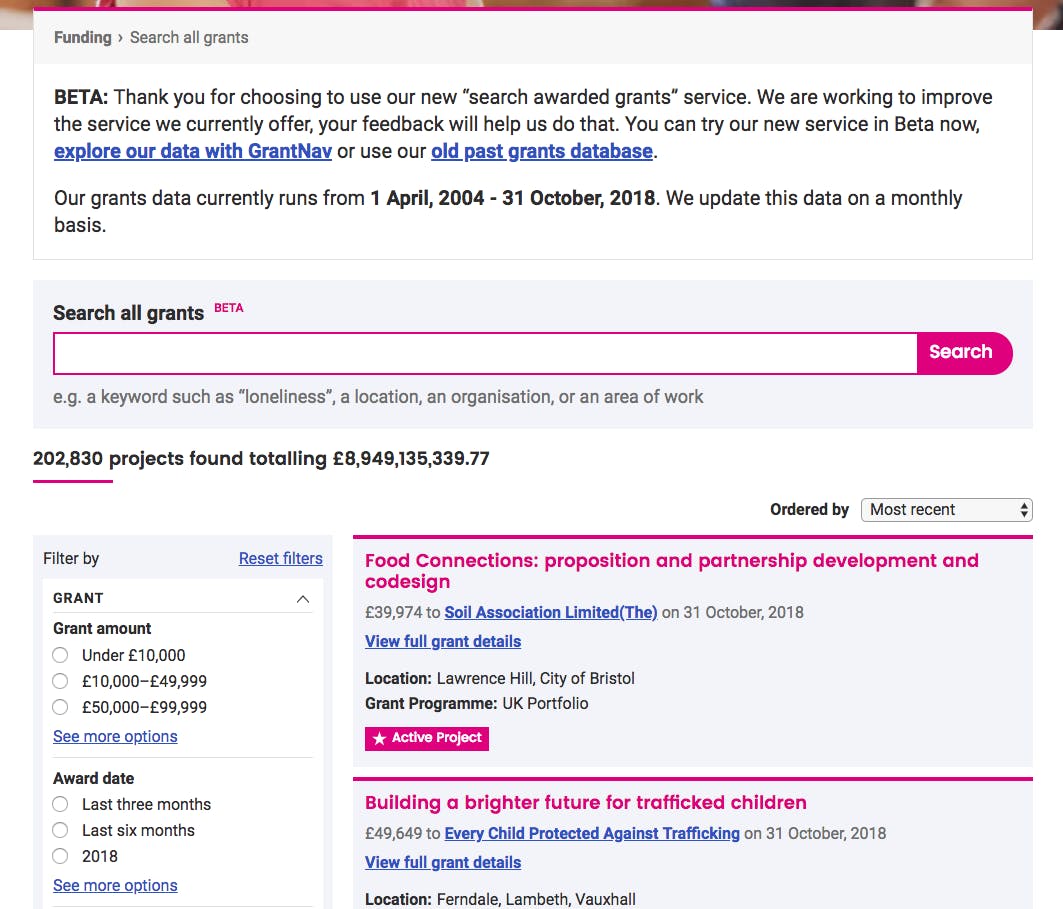
You can also see a side-by-side search on the new tool (left) versus the old (right).
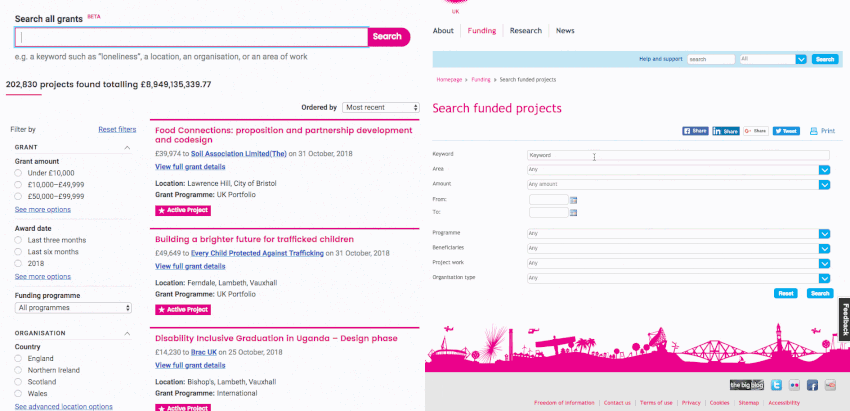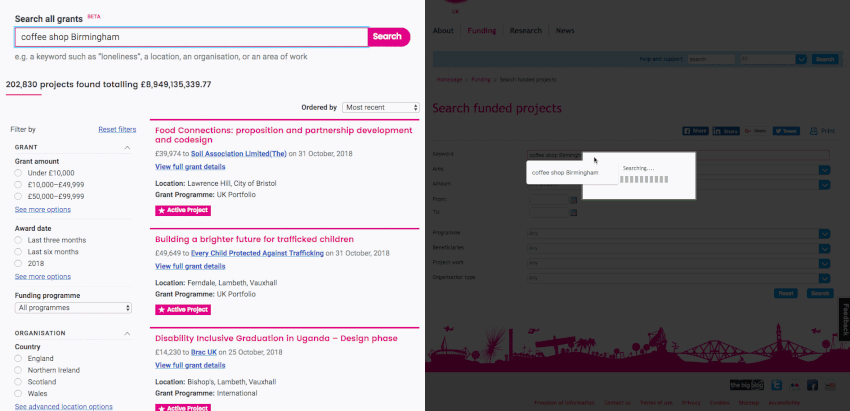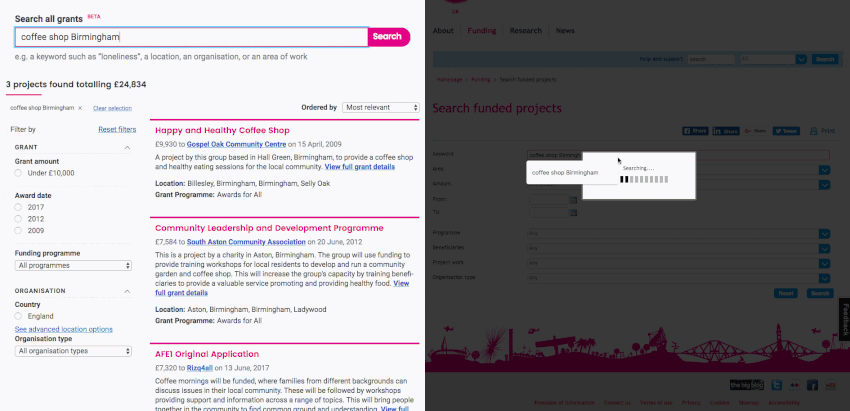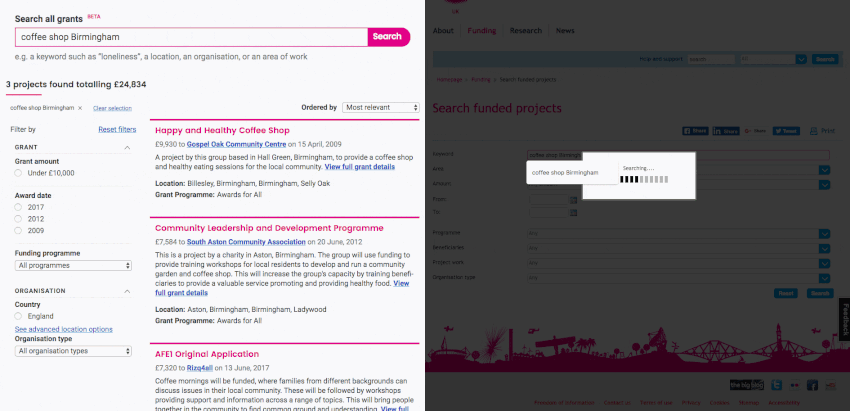
Since the new search tool went live, more users have spent more time using it and discovering new pages showing grant/recipient details from Google searches.
We still have things we want to improve but, for now, we’ve replaced a popular and important part of the website with something more usable allowing individuals and grant-makers to share data about what we’re funding with ease.